UTF-8 String

Swift 5 switches the preferred encoding of strings from UTF-16 to UTF-8 while preserving efficient Objective-C-interoperability. Because the String type abstracts away these low-level concerns, no source-code changes from developers should be necessary*, but it’s worth highlighting some of the benefits this move gives us now and in the future.
Switching to UTF-8 fulfills one of String’s long-term goals to enable high-performance processing, which is the most passionate request from performance-sensitive developers. It also lays the groundwork for providing even more performant APIs in the future. String’s preferred encoding is baked into Swift’s ABI for performance, so it was imperative that this switch happen in time for ABI stability in Swift 5.
* See “Use of String.Index.encodedOffset Considered Harmful” below for a potential change in behavior if misused
Background
A Change in Structure
Even though the String type is technically a struct, it can exist in many forms. You can think of String as an artisanal enum, hand-crafted using traditional bit-twiddling techniques in order to produce compact and efficient code.
Prior to Swift 5, string content could be in one of two native storage encodings: UTF-16 for Unicode-rich text, and a dedicated ASCII storage class when contents are all ASCII. In Swift 5, these two are replaced with a single UTF-8 storage encoding for both ASCII and Unicode-rich text.
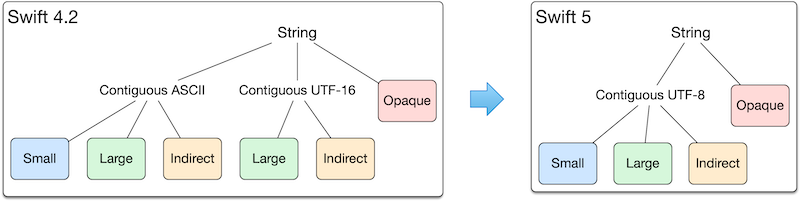
- Large strings are backed by a storage class with tail-allocated contents at a fixed offset from the object’s address.
- Small strings pack their contents directly in the String struct’s bits, skipping any allocation.
- Indirect strings are capable of providing a pointer and a length to contiguous contents through a resilient function call. (A resilient function’s behavior can be modified without breaking binary compatibility.)
- Opaque strings implement functionality only through resilient function calls, which means they can have any backing encoding or representation. This means new string forms can be added at any point in time. In exchange for this flexibility, they do not benefit from inlining and other optimizations.
String supports lazy-bridging, which means that NSStrings are not copied when imported into Swift. If a NSString is capable of providing a pointer to valid UTF-8 in contiguous memory (e.g. through CFStringGetCStringPtr), it is imported as an indirect string. Otherwise, it is imported as an opaque string.
For more technical details, see the recent Swift forum post Piercing the String Veil.
UTF-8: The Right Choice for Modern Computing
Native UTF-8 support is essential for efficient compatibility with modern computing environments, including:
- Server-side and client-side programming
- Systems programming and C interoperability
- Developer tools (build systems, editors, linters, etc.)
For example, source code (like most content) is encoded as UTF-8, so SourceKit represents and communicates positions in source code as offsets into a UTF-8 buffer. In Swift 4.2, writing an efficient client of a UTF-8 based service required maintaining a bidirectional index-mapping table from UTF-8 offsets to UTF-16 indices. Even forming a Swift 4.2 string from UTF-8 content involves transcoding the content to UTF-16, which can be expensive. For example, SwiftNIO saw a 20% speed improvement when serving up the homepage of swift.org by just upgrading to Swift 5, due to skipping this transcoding.
UTF-16 is used by systems designed during early versions of Unicode where all scalars could fit in 16 bits. Unfortunately, 16 bits ended up being too restrictive, and Unicode now uses 21-bit scalars. Swift 5 goes to great lengths to provide efficient interoperability with Objective-C and other UTF-16 based systems through amortized constant-time UTF-16 interfaces (see Breadcrumbs below). But, UTF-8 is the preferred and most efficient representation in Swift 5.
Differences in Encodings
Memory Density
For any ASCII portion of a string’s content, UTF-8 uses 50% less memory than UTF-16. For any portion comprised of latter-BMP scalars, UTF-8 uses 50% more memory than UTF-16. Both encodings are equivalent in size for most non-ASCII scalars from Latin/Greek-derived or Aramaic-derived scripts, as well as any non-BMP scalars (such as emoji).
| AB | ГД | いろは | 𓀀𓂀 | |
|---|---|---|---|---|
| Scalars | U+0041 U+0042 |
U+0413 U+0414 |
U+3044 U+308D U+306F |
U+13000 U+13080 |
| UTF-8 | 41 42 |
D0 93 D0 94 |
E3 81 84 E3 82 8D E3 81 AF |
F0 93 80 80 F0 93 82 80 |
| UTF-16 | 41 00 42 00 |
13 04 14 04 |
44 30 8D 30 6F 30 |
0C D8 00 DC 0C D8 80 DC |
* UTF-16 is endianness-dependent, this table lists the bytes in little-endian
Performance-sensitive string processing typically involves working with text that is heavily laden with ASCII, and this favors UTF-8. Even websites that consists almost entirely of Chinese prose (latter BMP scalars) are significantly smaller when encoded as UTF-8 due to the use of ASCII for HTML tags. Strings of user-presentable prose represent a small percentage of string usage, compared to programmer-presentable strings such as identifiers, log messages, URLs, textual formats, etc.
Swift 4.2’s dedicated ASCII representation could efficiently encode all-ASCII content. However, it is increasingly common, even for programmer-presentable strings, to have occasional non-ASCII content such as Unicode-rich punctuation. In Swift 4.2’s string model, a single non-ASCII scalar forces the entire content into UTF-16 storage.
Decoding and Validation Complexity
Both UTF-8 and UTF-16 are variable-width encodings, but UTF-16 is variable width up to 2 while UTF-8 is variable width up to 4. This makes UTF-16 simpler for decoding and on-the-fly validation for non-ASCII content. However, on modern processors and with Swift’s performance model, these advantages are overshadowed by the advantages of a single UTF-8 storage representation (see Unified Storage Representation below).
Modern computer systems have vector extensions and can be out-of-order, which can hide some of UTF-8’s (relatively) more complex decoding. Displaying user-presentable text in a UI requires more expensive computation than just decoding the underlying scalar values, diminishing the decoding advantage of UTF-16. Performance-sensitive string processing algorithms typically search for specific sequences of ASCII meta-characters amongst a sea of otherwise opaque bytes. UTF-8 is the ideal representation for this.
Swift 5, like Rust, performs encoding validation once on creation, when it is far more efficient to do so. NSStrings, which are lazily bridged (zero-copy) into Swift and use UTF-16, may contain invalid content (i.e. isolated surrogates). As in Swift 4.2, these are lazily validated when read from.
Immediate Benefits
Since this change has a major impact on the ABI, it had to be done for the Swift 5.0 release. While the decision to switch String’s encoding to UTF-8 was primarily motived by long-term plans that extend beyond the release (starting with SE-0247), even in Swift 5 this change brings significant benefits.
C Interoperability
Zero-terminated UTF-8 strings are C string compatible, and by maintaining zero-termination in our storage, native strings can interoperate with C without overhead. Code such as myString.withCString { … } no longer needs to allocate, transcode, and later free its contents in order to supply the closure with a C-compatible string. Instead, contiguous strings just provide their interior pointer (small strings are copied into temporary stack space).
Lazily bridged NSStrings still require a separate allocation/deallocation and transcoding.
Unified Storage Representation
As mentioned above, Swift 5 switches from two native storage representations to one. This allows for better analyses and more aggressive optimizations with fewer potential code-size or compilation time costs.
For example, inlining is a compiler optimization that can improve run-time performance at a potential cost to code size. In Swift 4.2, most string methods contained a pair of implementations, one for each storage representation. No matter what form a 4.2 string was in, an entire portion of potentially-inlined code wouldn’t even be run; this increases the cost and diminishes the benefits of inlining. Furthermore, the greatest benefits of inlining come from follow-on analyses and optimizations specific to one call-site, which are exponentially more difficult to perform on a dual representation. Swift 5’s unified storage representation is far more amenable to inlining and follow-on optimizations.
This unified storage representation also facilitated tiny tweaks and optimizations that individually deliver marginal gains, but combine multiplicatively to deliver significant performance improvements. Each of these was evaluated for Swift 4.2, but their benefits were diminished by the model complexity as they were costlier to retrofit on a dual-storage representation.
Unicode Small Strings
Swift 4.2 introduced a small-string representation on 64-bit platforms for strings of up to 15 ASCII code units in length without requiring an allocation or memory management. This couldn’t be extended to non-ASCII content with 4.2’s model without adding yet another encoding or small string representation, which as mentioned above carries significant downsides.
Since Swift 5 switched to UTF-8, small strings now support up to 15 UTF-8 code units in length without any significant downsides. This means your most important strings such as "smol 🐶! 😍" , can in fact, be smol.
This new design also benefits 32-bit platforms. While Swift 4.2 had no small string support, Swift 5 supports small strings of up to 10 UTF-8 code units on 32-bit platforms.
Impact on Existing Code
What Should I Change in My Code?
For the majority of developers, nothing!
If you found yourself dropping down to the UTF16View for performance reasons, reevaluate your benchmarking as many operations are faster in Swift 5. If you still need to drop down to something low level, the UTF8View is the most performant view for native strings.
For performance-sensitive code, String.UTF8View implements SE-0237 for native strings, meaning that you can execute a closure on contiguous UTF-8 bytes in memory by calling myString.utf8.withContiguousStorageIfAvailable { ... }. SE-0247 builds on this and offers even more convenience.
Use of String.Index.encodedOffset Considered Harmful String.Index.encodedOffset Considered Harmful section" href="#use-of-stringindexencodedoffset-considered-harmful">
SE-0241 deprecates String.Index.encodedOffset, as it had widespread misuse which was more likely to surface in Swift 5. It provides safe, more explicit index-mapping alternatives.
Objective-C Interoperability
String has always provided efficient interoperability with Objective-C APIs, and this is still the case for Swift 5. String’s backing storage classes are subclasses of NSString, so they bridge to Objective-C for free.
With the new UTF-8 backing, String provides direct access to its contents via Objective-C APIs in more situations, resulting in significant speedups when interacting with Swift strings bridged to Objective-C.
Switching to UTF-8 encoded contents presents a challenge for Objective-C interoperability, as Objective-C APIs are commonly expressed in terms of UTF-16 indices and lengths. Normally, converting from an arbitrary UTF-8 index to a UTF-16 index would be a linear time scan, but this would be an unacceptable performance cost for bridged strings. To get around this, native strings (only when requested) provide amortized constant time interchange between UTF-8 and UTF-16 indices by utilizing a breadcrumbing strategy.
Breadcrumbs
As we’ve seen, transcoding a string’s entire contents from UTF-16 to UTF-8 or vice-versa can be a costly operation. But, converting a UTF-16 offset to a UTF-8 offset is a very fast linear scan, essentially summing the high-bits on all the bytes. The very first time an API assuming O(1) access to UTF-16 is used on a large string, it performs this scan and leave breadcrumbs at fixed strides so that it can answer subsequent calls in amortized O(1) time.
The breadcrumbs store an Array of string indices and the length of the string in UTF-16 code units. The ith breadcrumb corresponds to the i * stride UTF-16 offset. Mapping a UTF-16 offset to a UTF-8 offset to access our contents starts at breadcrumbs[offset / stride] and scans forwards from there. Mapping from a UTF-8 offset to a UTF-16 offset (less common) starts with a reasonable estimate and does a binary search from there to find an upper bound and lower bound for the subsequent scan.
Breadcrumb granularity gives us a way to balance between speed and size. Calculating breadcrumbs, their granularity, and even their representation is behind a resilient function call, so all of this can be tweaked and adjusted in the future.
Currently, strings use a very fine granularity, tilting strongly towards speed out of a desire to not introduce unanticipated regressions in any realistic situation. Strings comprised of latter-BMP scalars which have these APIs called on them have a very low memory footprint on the system overall, so memory pressure is not a common concern. As the performance of this scan is improved, granularity can be increased without harming speed.
ASCII is an encoding subset of UTF-16, which means UTF-8 offsets are the same as UTF-16 offsets if the string is entirely in ASCII. All-ASCII strings skip breadcrumbing and just return the answer.
Performance in Your Code
Any significant model change has the risk of performance regressions in some scenarios. If you encounter any, or if you have some performance-sensitive code that should be faster, please file a bug. String will keep delivering performance improvements every release, and user reports help identify and prioritize them.
Questions?
Please feel free to post questions about this post on the associated thread on the Swift forums.